 News
News
Blue Brain Nexus Forge: Building and using Knowledge Graphs made easy
 Research Team
Research Team
Image: © 2020 EPFL
A deluge in digital data, the trend for cross-disciplinary and multi-modal scientific investigations along with the tremendous computing power now available, has led to team based, data-driven and data-intensive methods commonly used in science. These advances also come with a set of challenges summarized in the FAIR guiding principles for research data management - make heterogeneous data generated from different contexts, Findable, Accessible, Interoperable and Reusable. Accordingly, Knowledge Graphs have become the go-to key solution across both research and industry to address these challenges.
In a Knowledge Graph, data and factual knowledge can be structured and described as entities of interest with rich and actionable metadata detailing their provenance. Their connection can be described across organizations’ databases and systems to break data and knowledge silos, and increase data findability and accessibility. Furthermore, a Knowledge Graph enables an organization to define and share its core scientific and business concepts as well as vocabulary, using expressive data models and schemas such as ontologies, therefore enabling useful data recommendation as well as workflows interoperability.
As a data-driven science project with the goal to build biologically detailed digital reconstructions and simulations of the mouse brain, the Swiss brain research initiative, EPFL’s Blue Brain Project faces these same challenges. To address them, the Blue Brain Project open sourced Blue Brain Nexus – a culmination of many years of research into building a state-of-the-art semantic Data and Knowledge Graph management system enabling the FAIR principles for the Neuroscience and broader scientific community.
Yet, building and using Knowledge Graphs often require many components ranging from data transformations, ontologies and schemas defining the targeted Knowledge Graph domain, scalable stores for managing the resulting graph, as well as data and factual knowledge search and access. While many systems and tools that implement these components exist separately, they often come with a high level of complexity when dealing with data, ontologies and schemas even for data scientists as well as data and knowledge engineers.
To make building and using Knowledge Graphs simpler and more consistent, the Blue Brain team has open sourced Blue Brain Nexus Forge - enabling data scientists, data and knowledge engineers to uniquely combine all these components under a consistent, single and generic Python Framework. “Blue Brain Nexus Forge is an important new part of the Nexus ecosystem enabling data scientists to readily build and use the power of Knowledge Graphs to accelerate the knowledge discovery process,” explains Blue Brain Director, Sean Hill.
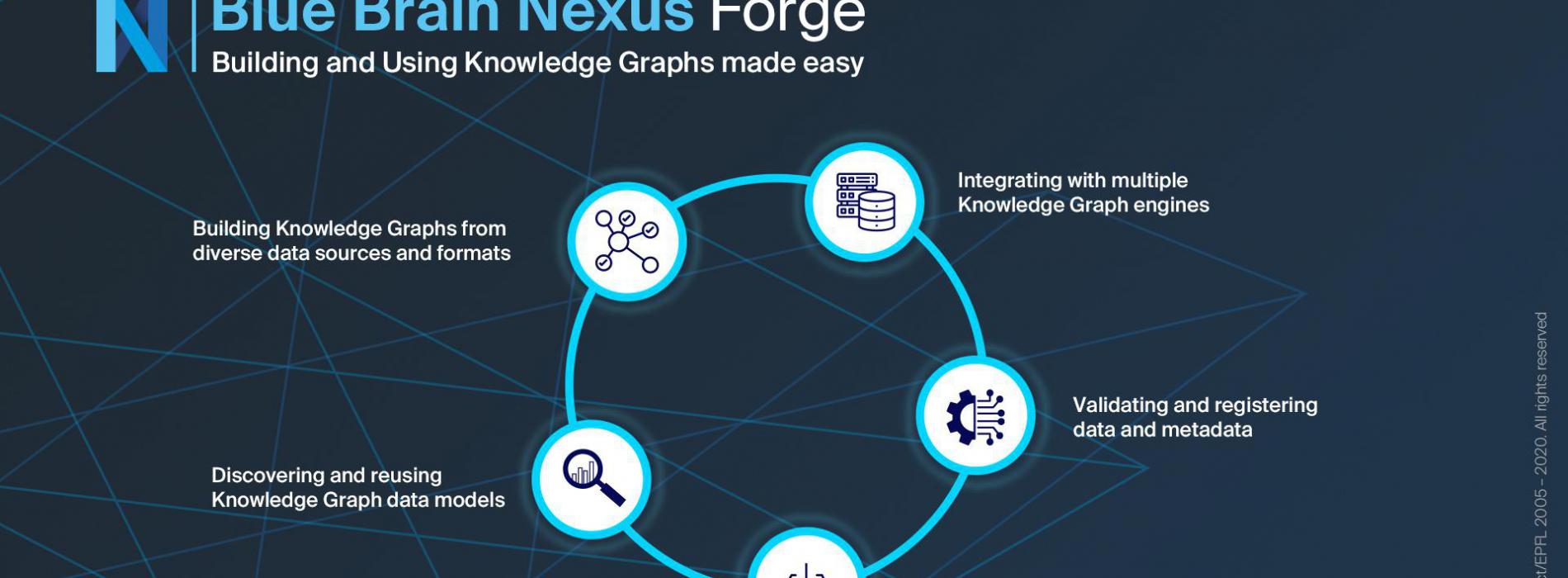
With Blue Brain Nexus Forge, non-expert users can build and use Knowledge Graphs to:
- Discover and reuse data models such as ontologies and schemas to shape, constrain, link and add semantics to datasets
- Build Knowledge Graphs from heterogeneous sources and formats: defining, executing and sharing data mappers to transform data from a source format to a target one conformant to schemas and ontologies
- Integrate with various stores for Knowledge Graph storage, management, scaling capabilities, data search and access
- Validate and register data and metadata
- Search and download data and metadata from a Knowledge Graph without the complexity of underlying technologies such as RDF (Resource Description Framework).
Go to Blue Brain Nexus Forge – https://nexus-forge.readthedocs.io
Release Notes - https://nexus-forge.readthedocs.io/en/latest/releases/v0.3-release-notes.html
For more information, please contact Blue Brain Communications Manager – kate.mullins@epfl.ch